About
I am a postdoctoral researcher specializing in the sound field with a focus on deep learning. Through my expertise in research and my experiences as a sound engineer, I aim to contribute meaningfully to the advances of the audio research field. Here, you'll find details about my academic journey, skills, and projects. Thank you for taking the time to visit !
Education
Nantes, France
Degree: PhD in Computer Science (ongoing)
- Deep Learning
- Acoustics
- Cartography
Relevant Courseworks:
École Nationale Supérieure Louis-Lumière
Saint-Denis, France
Degree: Master in Sound
- Sound Recording
- Acoustics and Psychoacoustics
- Film Sound Design
- Audio Post-Production
Relevant Courseworks:
Châlons-en-Champagne, France
Degree: Engineer Diploma
- Mechanics
- Database Management Systems
- Operating Systems
- Electronics
Relevant Courseworks:
Bari, Italy
Degree: Master in Mechanical Engineering
- Mechanics Applied to Aeronautics
- Management of Innovation
- Labor Law
Relevant Courseworks:
Experience

Perceptual enhancement of sound environments and speech using audio concealing techniques
👉 Deep learning: generative models, TTS (Text-to-Speech) and ASR (Automatic Speech Recognition) models
👉 Statistical analysis, experimental design, auditory perception, cognitive psychology
👉 Acoustic scene analysis, audio signal processing, programming (Python)
Skills: Computer Science, Statistics, Python, Deep Learning, Acoustics, Cartography
Sound source detection for the sensitive mapping of urban sound environments.
👉 Deep Learning: classification, generative models
👉 Statistical analysis, experimental design, auditory perception, cognitive psychology
👉 Acoustic scene analysis, audio signal processing, programming (Python)
Skills: Computer Science, Statistics, Python, Deep Learning, Acoustics, Cartography

Teaching students from the 1st to the 3rd cycle at Ecole Centrale de Nantes (ECN) (approximately 100h). Supervision of
a master's student internship, of 2 masters students' thesis at Ecole Nationale Supérieure Louis-Lumière (ENSLL),
and of 4 master's students projects.
👉 Deep Learning
👉 algorithms and programming
👉 signal processing
👉 SQL database
Skills: Pedagogy, Python, C++, SQL, Deep Learning, Acoustics

Freelance sound engineer working for radio, music and cinema
👉 Sound mixing and sound editing for the cinema industry, for music, and for sound fictions
👉 Direction of a radio program for Prun' radio
Projects
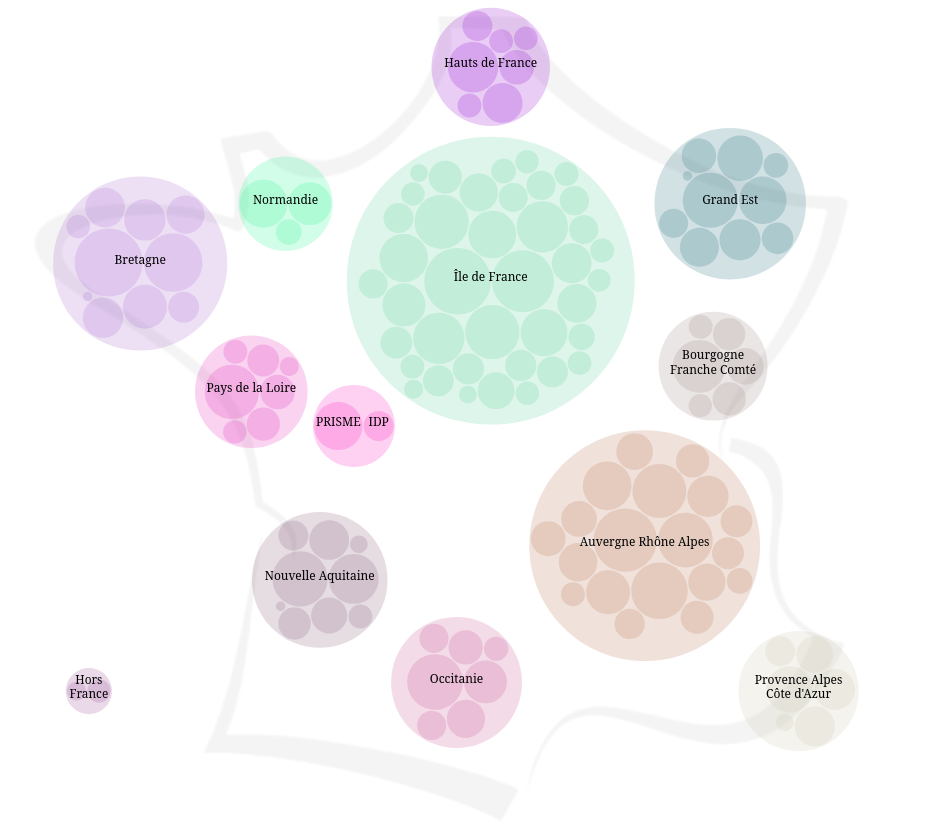
I created a dynamic visualization that maps the various research areas within the IASIS research group. The visualization uses a circle-packing layout: the more people involved in a research area, the larger its corresponding bubble. Two complementary views are available. In the first, the top-level bubbles represent regions of France, followed by laboratories or companies, and finally the research areas. In the second view, the hierarchy is reversed: it starts with research areas, then shows the affiliated labs or companies. This interactive tool allows users to explore the network's structure and identify key areas of expertise accross the institutions involved.

Organizer and dataset creator for DCASE Task 7: Sound Scene Synthesis, part of the DCASE 2024 Challenge. I led the dataset design and collection, defined the task protocol, and helped in coordinating the evaluation setup. The task focuses on generating realistic urban sound scenes from textual descriptions. It aims to support the development of generative models for urban soundscapes.
Datasets

Extreme Metal Vocals Dataset (EMVD) is a dataset of extreme vocal distortion techniques used in heavy metal
The dataset consists of 760 audio excerpts of 1 second to 30 seconds long, totaling about 100 min of audio material, roughly composed of 60 minutes of distorted voices and 40 minutes of clear voice recordings. These vocal recordings are from 27 different singers and are provided without accompanying musical instruments or post-processing effects.

This dataset supports the development and evaluation of generative algorithms for environmental sound synthesis.
The DCASE 2024 Task 7 Dataset - Open Source dataset includes 310 audio clips, each 4 seconds long, along with their corresponding text prompts. Unlike typical audio captioning datasets, both the prompts and audio scenes were manually crafted and edited. This enables a more controlled and quantifiable evaluation of generative models.

Publications
Journals

The exploration of the soundscape relies strongly on the characterization of the sound sources in the sound environment. Novel sound source classifiers, called pre-trained audio neural networks (PANNs), are capable of predicting the presence of more than 500 diverse sound sources. Nevertheless, PANNs models use fine Mel spectro-temporal representations as input, whereas sensors of an urban noise monitoring network often record fast third-octaves data, which have significantly lower spectro-temporal resolution. In a previous study, we developed a transcoder to transform fast third-octaves into the fine Mel spectro-temporal representation used as input of PANNs. In this paper, we demonstrate that employing PANNs with fast third-octaves data, processed through this transcoder, does not strongly degrade the classifier's performance in predicting the perceived time of presence of sound sources. Through a qualitative analysis of a large-scale fast third-octave dataset, we also illustrate the potential of this tool in opening new perspectives and applications for monitoring the soundscapes of cities.
International Conferences

Third octave spectral recording of acoustic sensor data is an effective way of measuring the environment. While there is strong evidence that slow (1s frame, 1 Hz rate) and fast (125ms frame, 8Hz rate) versions lead by-design to unintelligible speech if reconstructed, the advent of high quality reconstruction methods based on diffusion may pose a threat, as those approaches can embed a significant amount of a priori knowledge when learned over extensive speech datasets.
This paper aims to assess this risk at three levels of attacks with a growing level of a priori knowledge considered at the learning of the diffusion model, a) none, b) multi-speaker data excluding the target speaker and c) target speaker. Without any prior regarding the speech profile of the speaker (levels a and b), our results suggest a rather low risk as the worderror-rate both for humans and automatic recognition remains higher than 89%.

Urban noise maps and noise visualizations traditionally provide macroscopic representations of noise levels across cities. However, those representations fail at accurately gauging the sound perception associated with these sound environments, as perception highly depends on the sound sources involved. This paper aims at analyzing the need for the representations of sound sources, by identifying the urban stakeholders for whom such representations are assumed to be of importance. Through spoken interviews with various urban stakeholders, we have gained insight into current practices, the strengths and weaknesses of existing tools and the relevance of incorporating sound sources into existing urban sound environment representations. Three distinct use of sound source representations emerged in this study: 1) noise-related complaints for industrials and specialized citizens, 2) soundscape quality assessment for citizens, and 3) guidance for urban planners. Findings also reveal diverse perspectives for the use of visualizations, which should use indicators adapted to the target audience, and enable data accessibility.

This paper explores whether considering alternative domain-specific embeddings to calculate the Fréchet Audio Distance (FAD) metric can help the FAD to correlate better with perceptual ratings of environmental sounds. We used embeddings from VGGish, PANNs, MS-CLAP, L-CLAP, and MERT, which are tailored for either music or environmental sound evaluation. The FAD scores were calculated for sounds from the DCASE 2023 Task 7 dataset. Using perceptual data from the same task, we find that PANNs-WGM-LogMel produces the best correlation between FAD scores and perceptual ratings of both audio quality and perceived fit with a Spearman correlation higher than 0.5. We also find that music-specific embeddings resulted in significantly lower results. Interestingly, VGGish, the embedding used for the original Fréchet calculation, yielded a correlation below 0.1. These results underscore the critical importance of the choice of embedding for the FAD metric design.

In this paper, we introduce the Extreme Metal Vocals Dataset, which comprises a collection of recordings of extreme vocal techniques performed within the realm of heavy metal music. The dataset consists of 760 audio excerpts of 1 second to 30 seconds long, totaling about 100 min of audio material, roughly composed of 60 minutes of distorted voices and 40 minutes of clear voice recordings. These vocal recordings are from 27 different singers and are provided without accompanying musical instruments or post-processing effects. The distortion taxonomy within this dataset encompasses four distinct distortion techniques and three vocal effects, all performed in different pitch ranges. Performance of a state-of-the-art deep learning model is evaluated for two different classification tasks related to vocal techniques, demonstrating the potential of this resource for the audio processing community.
International Workshops

Oxygenators, alarm devices, and footsteps are some of the most common sound sources in a hospital. Detecting them has scientific value for environmental psychology but comes with challenges of its own: namely, privacy preservation and limited labeled data. In this paper, we address these two challenges via a combination of edge computing and cloud computing. For privacy preservation, we have designed an acoustic sensor which computes third-octave spectrograms on the fly instead of recording audio waveforms. For sample-efficient machine learning, we have repurposed a pretrained audio neural network (PANN) via spectral transcoding and label space adaptation. A small-scale study in a neonatological intensive care unit (NICU) confirms that the time series of detected events align with another modality of measurement: i.e., electronic badges for parents and healthcare professionals. Hence, this paper demonstrates the feasibility of polyphonic machine listening in a hospital ward while guaranteeing privacy by design.

Slow or fast third-octave bands representations (with a frame resp. every 1-s and 125-ms) have been a de facto standard for urban acoustics, used for example in long-term monitoring applications. It has the advantages of requiring few storage capabilities and of preserving privacy. As most audio classification algorithms take Mel spectral representations with very fast time weighting (ex. 10- ms) as input, very few studies have tackled classification tasks using other kinds of spectral representations of audio such as slow or fast third-octave spectra.
In this paper, we present a convolutional neural network ar- chitecture for transcoding fast third-octave spectrograms into Mel spectrograms, so that it could be used as input for robust pre-trained models such as YAMNet or PANN models. Compared to training a model that would take fast third-octave spectrograms as input, this approach is more effective and requires less training effort. Even if a fast third-octave spectrogram is less precise both on time and frequency dimensions, experiments show that the proposed method still allows for classification accuracy of 62.4% on UrbanSound8k and 0.44 macro AUPRC on SONYC-UST.